Agentic Architecture for Athena
How I designed Athena as a product-facing agent system: workflow-first orchestration, explicit artifacts, and UX that helps humans and AI collaborate.
Athena started as a workflow problem, and it became an orchestration problem almost immediately. Once I had retrieval working, the harder question was how to make an agent feel reliable inside a real product experience: clarify user intent, choose tools deterministically, search deeply enough to be useful, and still return something understandable to a mixed technical audience. I did not want a generic “chatbot with tools.” I wanted a system that could support planning, collaboration, and implementation handoff without relying on invisible model memory.
Start with the workflow, not the model
The most important design decision in Athena was deciding what the agent was actually responsible for. I did not want it to be an all-purpose answer machine. Its job was narrower: help users understand a workflow, retrieve the right technical evidence, and turn that evidence into artifacts people could use. In practice, that meant diagrams, source-backed answers, structured implementation plans, and eventually portable exports that could move into coding environments.
That decision shaped the architecture. Instead of a simple prompt and tool list, the runtime had to support a loop: classify the query, activate the right tools, retrieve evidence, validate the search quality, and only then respond. It also had to produce different kinds of outputs depending on the workflow stage. A planning answer, a visual flow, and a Bridge export all come from the same underlying system, but they are not the same user experience.
The main chat graph
Athena’s core chat runtime is a stateful graph rather than a single prompt call. The graph starts with a query classifier, then routes into the main agent, tool execution, a retrieval-quality judge, a search gate, and a response filter. The important thing is not that it uses a graph library; it is that the system explicitly models where the agent is allowed to continue, where it must go search again, and where a response is considered finished.
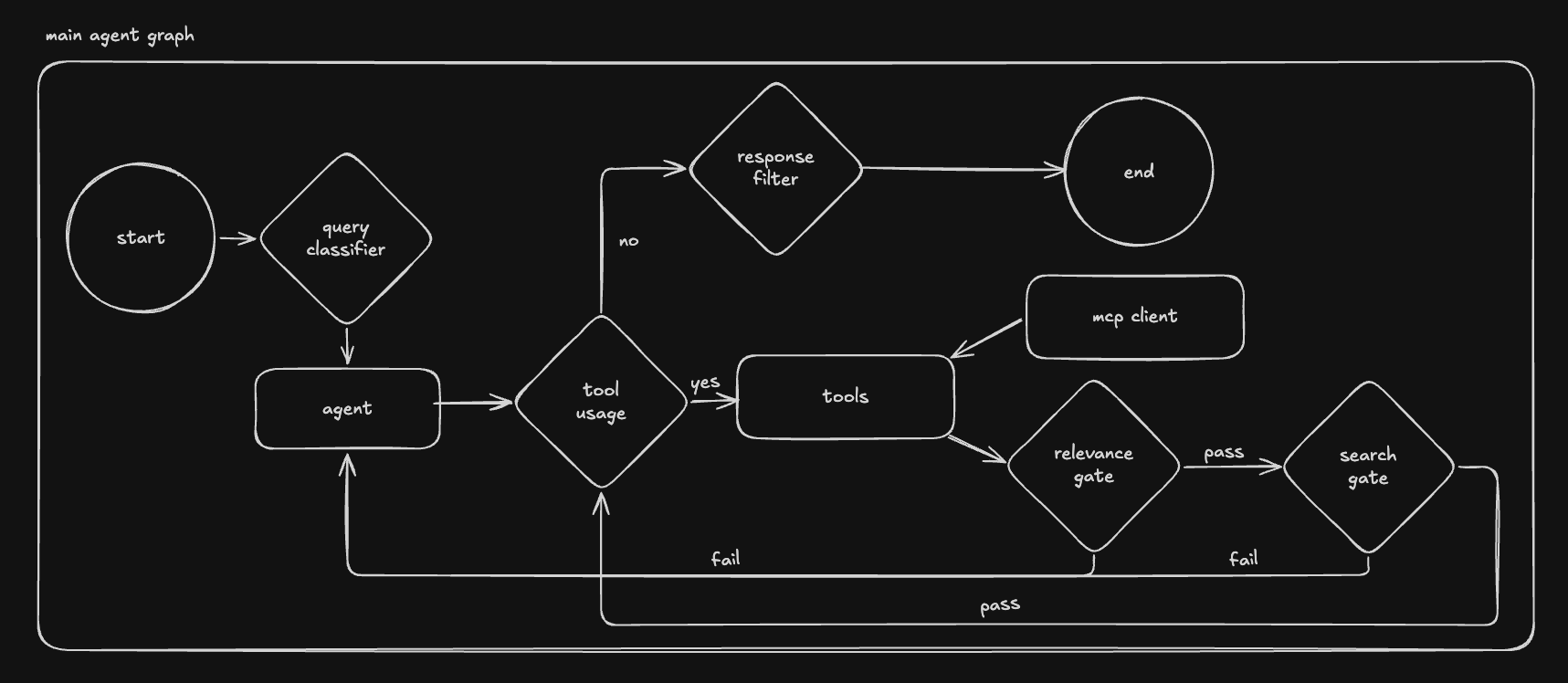
This structure made the product much easier to reason about. When something went wrong, I could ask whether the issue lived in classification, tool choice, retrieval quality, response formatting, or the handoff between them. It also made it possible to build the rest of the product around explicit state transitions rather than vibes. That matters a lot when the UI is streaming thought-process steps, rendering diagrams, and opening workflow panels while the model is still working.
Why I added an LLM-as-a-judge layer
One of the first failure modes I saw was that “retrieval worked” was too low a bar. Search could return results that looked plausible but were semantically wrong for the user’s actual question. For example, a property name might look relevant while describing a completely different behavior in context. So I added a relevance gate: after search, a smaller model evaluates whether the latest result batch actually answers the user’s question, and if not, it injects better search terms back into the graph and retries.
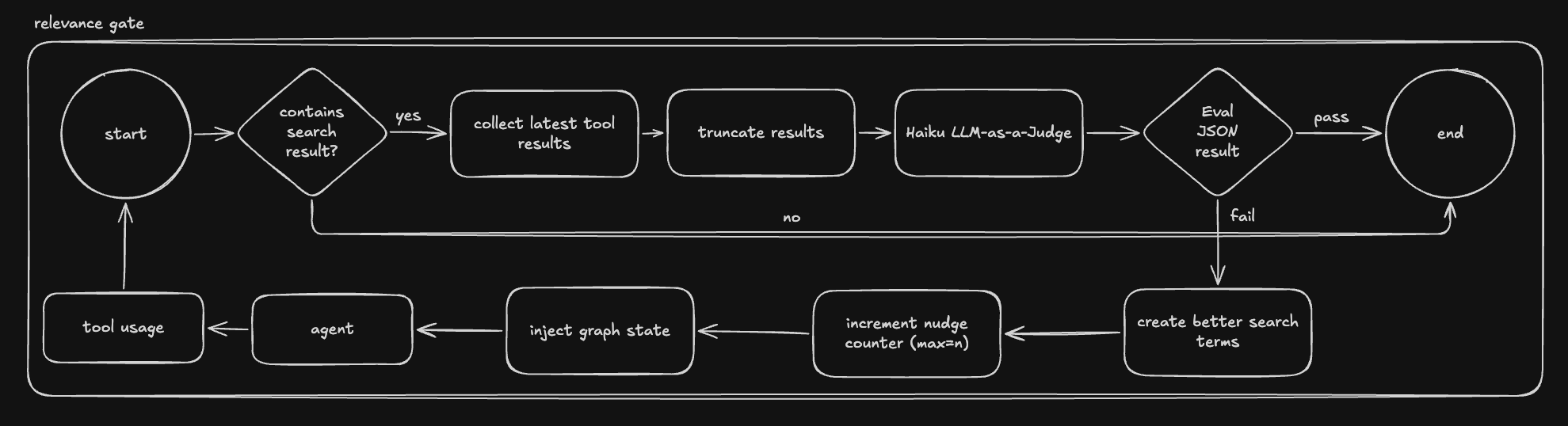
This was one of the most useful architecture decisions in Athena because it improved trust without requiring a dramatically larger model. Instead of assuming the first retrieval pass was good enough, the system explicitly challenged its own search quality. That is a pattern I now think of as a product feature, not just an AI trick. Users care that the result feels grounded and specific to their problem; they do not care whether that reliability came from a better prompt or a judge loop.
The search gate is really a product policy layer
The search gate looks technical, but conceptually it is a product policy engine. It tracks how much search has already happened, what evidence types were retrieved, whether a domain-specific compatibility question has actually been verified, and whether the current tool context matches the user’s intent. If those checks fail, it injects hidden graph-state nudges and sends control back to the agent. If they pass, the graph is allowed to keep moving.
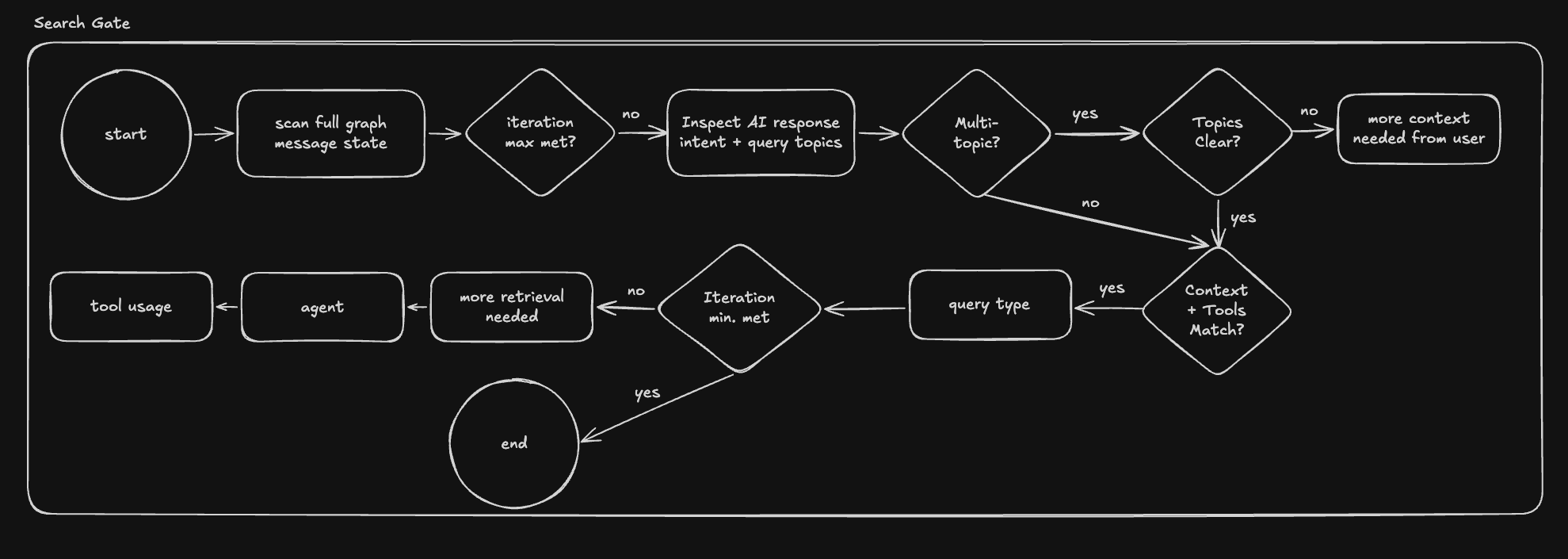
I liked this structure because it separated “the model wants to answer” from “the system considers the answer sufficiently grounded.” In many agent demos those two things are the same, which is exactly why they feel impressive in a demo and unreliable in production. Athena needed a stronger contract because its outputs were often being shared across teams or exported into downstream developer workflows.
The response filter is the last contract before the user
Even after retrieval has been judged and the search gate has approved an answer, the response itself still needs to meet a contract. The response filter is the final subgraph in the runtime: it enforces formatting rules, applies safety and tone checks, validates citations, and ensures the output matches the workflow stage the user is in. Only after passing the filter does the response actually leave the system.
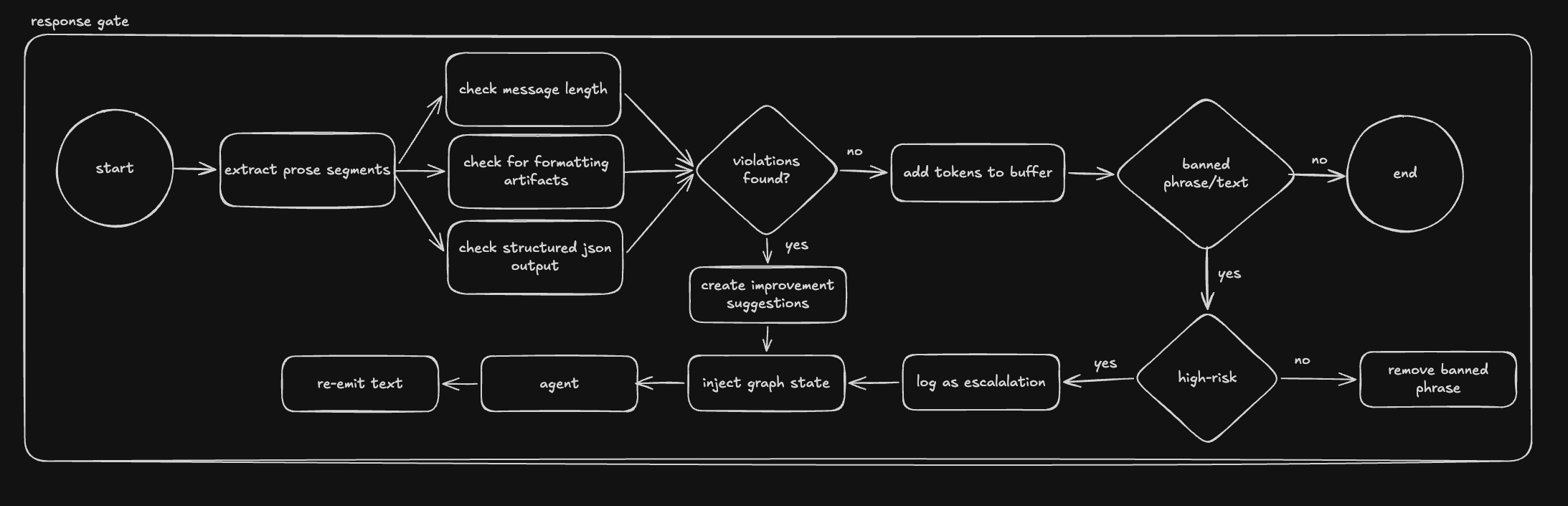
Treating the response itself as a gated artifact, rather than a raw model output, was important for the same reason the search gate mattered: downstream products consume these responses as inputs. A planning artifact, a diagram, or a Bridge export all assume the response is well-formed and trustworthy. The filter is what makes that assumption safe.
Explicit artifacts beat hidden memory
Another major architectural choice was preferring explicit artifacts over hidden agent state. Athena does use conversation history and context, but I did not want the value of a session to disappear into a long chat transcript. That is why the product kept evolving toward diagrams, shareable links, embedded tables, and Bridge workflows. Those artifacts gave users something stable to discuss, edit, and hand off.
This is also why I would describe Athena as single-agent orchestration with artifact-based handoffs, not as a pure multi-agent system. The main user-facing runtime is one orchestrated agent graph, but its outputs are designed to become inputs to later workflows. Planning becomes a workflow artifact. That artifact can be shared in the browser, turned into a Bridge export, or used to seed Studio experimentation. The orchestration is in the state machine, but the continuity is in the artifacts.
UX is part of the architecture
I think a lot of agent writing still treats the UI as a wrapper around the model. In Athena, the UI is part of the architecture itself. Streaming thought-process steps, surfacing sources, rendering diagrams, and deciding when a workflow should become shareable or embeddable are all part of how the system earns user trust. If I had only focused on prompts and retrieval quality, I could have built a technically impressive system that still felt opaque and hard to adopt.
That is probably my biggest takeaway from Athena: good agent architecture is not just about routing and tool calls. It is about deciding where the model should think, where the system should intervene, and where the user needs a stable object they can understand and act on. For Athena, that meant building a graph that could validate itself, then designing the product so the output of that graph became useful beyond the chat window.