Building RAG Systems That Are Actually Usable
A practical look at the retrieval layer behind Athena: ingestion, metadata, reranking, MCP tool surfaces, and why good RAG systems are workflow products.
The phrase “build a RAG system” sounds deceptively small. In practice, a usable retrieval system is not just a vector database and embeddings. It is a document-processing pipeline, a schema design problem, a query interface, and a trust problem. I learned that quickly while building Athena’s knowledge layer, where the source material ranged from PDFs and HTML docs to markdown, tables, and code.
Ingestion is where retrieval quality really starts
The main mistake people make with RAG is treating ingestion as a preprocessing chore rather than a product decision. In Athena, source documents were not uniform. Some content lived in PDFs, some in markdown, some in HTML, some in code examples, and some in tabular reference material. If all of that gets flattened carelessly, the vector database may still return “results,” but those results will be hard to trust and even harder to use inside an agent workflow.
So I approached ingestion as a typed pipeline. Source documents first go through routing, then format-specific extraction, then transformation into normalized JSON, then chunking, metadata enrichment, embedding, and finally indexing. That gave me a chance to preserve useful distinctions between content types instead of pretending everything was just text. In practice, those distinctions mattered later when the agent needed to answer questions differently for API signatures, conceptual guides, compatibility tables, and code examples.
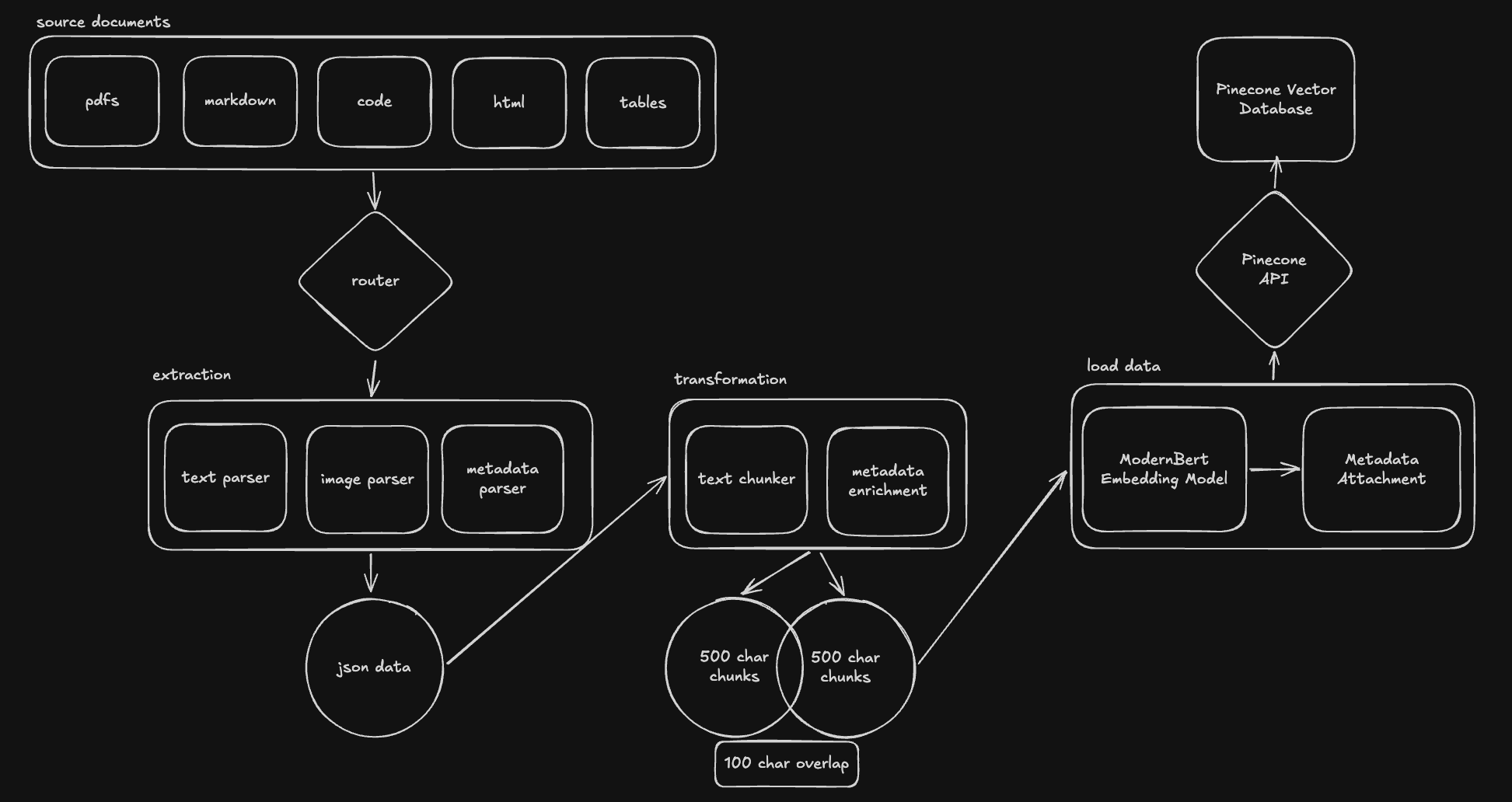
Chunking is not just a token limit problem
The chunking strategy matters more than most people admit. Athena used relatively small chunks with overlap and metadata enrichment because the goal was not merely recall; it was to return chunks that could later be reranked, cited, and reasoned over by an LLM. If a chunk is too large, it hides the relevant detail in noise. If it is too small, the system loses the structure that makes the result interpretable.
I also found that metadata is what turns a vector store into a usable retrieval system. Source type, document path, SDK version, content category, and other normalized attributes made reranking and tool usage much more effective. When users ask workflow-level questions, they usually do not want the nearest semantic paragraph; they want the right type of evidence. Good metadata gives the system a chance to tell those differences apart.
Retrieval is a system, not a single search call
Once documents are indexed, the next temptation is to believe the hard part is done. In Athena, the useful retrieval system actually had several layers: embeddings and vector search, metadata-aware filtering, reranking, tool surfaces exposed through MCP, and then downstream validation inside the agent graph. That is why I think of the retrieval layer as a product subsystem, not an implementation detail.

The MCP layer mattered because it turned the retrieval system into something other products and agents could actually use. Instead of writing bespoke retrieval logic into every app, I could expose search, context, and documentation access as reusable tools. That helped Athena, but it also mattered for Bridge and local coding-agent workflows. In other words, the retrieval system became more valuable once it was designed as a platform.
Why reranking and judges matter
Another lesson I learned is that nearest-neighbor retrieval is not enough for real workflows. Search often returned plausible-looking matches that were technically wrong for the user’s specific question. That is why I added reranking and later an LLM-as-a-judge layer in Athena. The vector database was responsible for broad semantic recall; reranking and judges were responsible for tightening the answer quality before the system responded with confidence.
This is the difference between “the search returned something relevant” and “the product returned something trustworthy.” The latter is much more expensive to design, but it is the threshold that matters when users are making planning or implementation decisions. A retrieval layer that cannot help the product distinguish between vague relevance and actionable evidence will eventually push that uncertainty onto the user.
The real output is confidence, not context
The most important shift in my thinking was realizing that the real output of a good RAG system is not context window stuffing. It is user confidence. That confidence comes from grounded results, source traceability, stable tool interfaces, and enough structure that the system can explain why it chose a result. In Athena, the vector database was necessary, but it was never the product. The product was the confidence users built when retrieval, orchestration, and UX all worked together.
If I were extending this system further, I would invest more in retrieval observability and evaluation earlier. Chunking, metadata design, and reranking all look reasonable in isolation, but the real signal comes from usage: which documents are repeatedly useful, where search quality drops off, and which query patterns need new retrieval strategies. That is why I now think the best RAG systems are not “search systems with LLMs attached.” They are product systems built around the workflow of finding, validating, and acting on the right evidence.